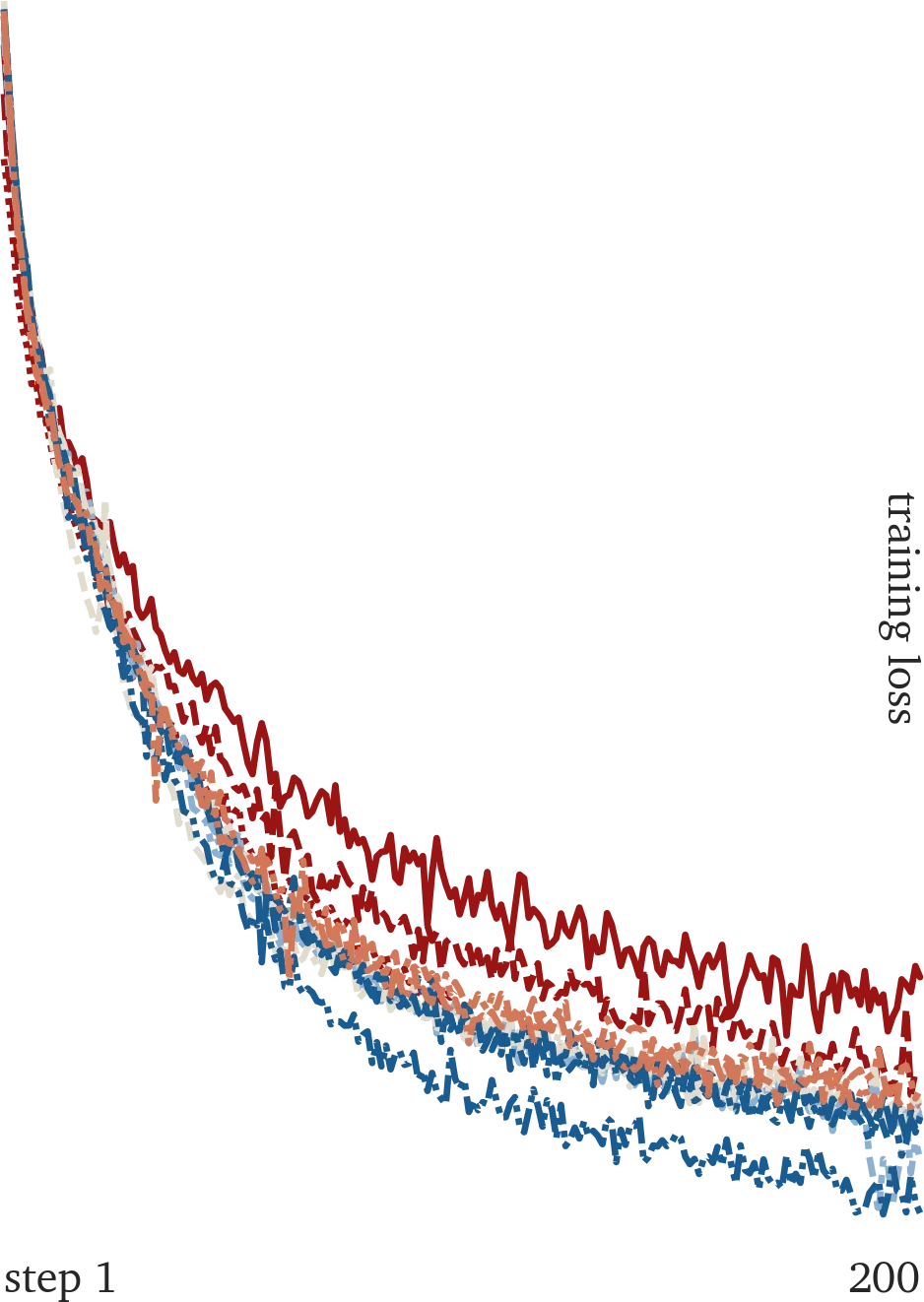
I spent my free time for the past year learning about neural networks by training a 500M parameter transformer mostly from scratch (source code here (opens in new tab)). I’d say the results are unremarkable, but I learned so many things that I never learned taking ML in college a year prior. From talking to friends who also took similar courses, this seems to be the normal experience…
Don’t get me wrong, I don’t mean to criticize - college intentionally focuses more on the theory over the engineering, which I would rather have a teacher guiding me through. The field has changed a lot in both fronts within the past decade though, and most curricula have not caught up with either!
I thought it would be fun to talk about some of the stuff I learned for my first blog post, especially what would have been useful to know before going into this. I don’t want to talk about the specific technical details since that can get overwhelming very fast, and there’s plenty of resources discussing them. As well, I hope this keeps the ideas clean regardless of the architecture.0Most of this post also assumes you have some constraints on time / budget / compute. The paradigm changes when you have lots of resources and a great pressure to compete. You wouldn’t be reading this if that’s your case I assume, but there might be some stuff for you here :)
What outdated curricula miss
I didn’t dive far into neural networks because I assumed that scaling neural networks was too difficult. The loss landscape was too jagged and it would be difficult to find a good minimum. They suffer from vanishing gradients and other instability problems. They were very fussy - needing to tune hyperparameters carefully by testing many different configurations with the full training sequence each time.
These assumptions were based on knowledge from a curriculum that doesn’t reflect modern findings in ML. Most of those problems aren’t a big deal.
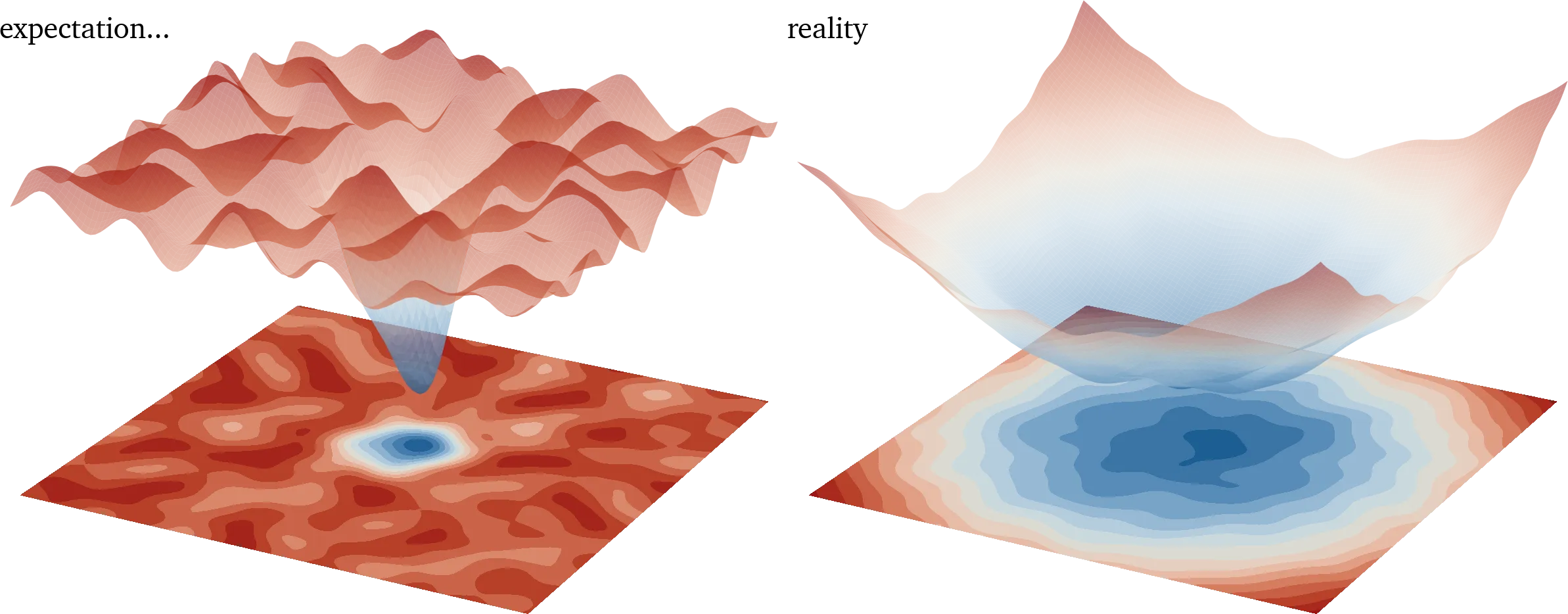
- The loss landscape is smooth enough such that optimizers won’t be likely to get stuck in local minima, and in fact a true local minimum is statistically unlikely. Below’s an exaggeration of that.1Hand-wavey proof: for a minimum to exist, it must be a minimum in every single dimension. With a dimensional size of 500 million for example, this is incredibly rare.
- Vanishing gradients can be fixed by using residual connections, which decreases the amount of layers gradients must pass through to provide learning signal to the earliest layers.
- Hyperparameters tend to be mostly independent, so you can optimize them one at a time. (An example of an exception is learning rate + batch size; with things like these you’d scale them together.)
- Improvements are usually evident at the start of training so you don’t need to launch the full training procedure to compare two versions accurately; a change that looks worse early rarely flips to better later. (An example of an exception to this is really any regularization technique.)
Another major change is the data. In the 2010s, the inherent scarcity of clean labeled data was a major bottleneck for training large neural networks independent of architecture. Focusing on self-supervised pretraining allows using the whole internet as data, and modern features like attention are able to capture information much more effectively.
Richard Sutton’s ‘The Bitter Lesson’ (opens in new tab) argues that due to the rapid improvements in hardware, general models that leverage and keep pace with increasing compute (and in this case, data) are more favorable than brittle models carefully designed over human intuition and knowledge. Similarly (but not directly), favoring increasing scale over clever architecture tricks to get performance gains has proved to be the better decision given the resources are available.
Weigh expected value versus effort
However, ‘The Bitter Lesson’ is not an excuse to make an inefficient model. The best way to get a good model is through iterative development:
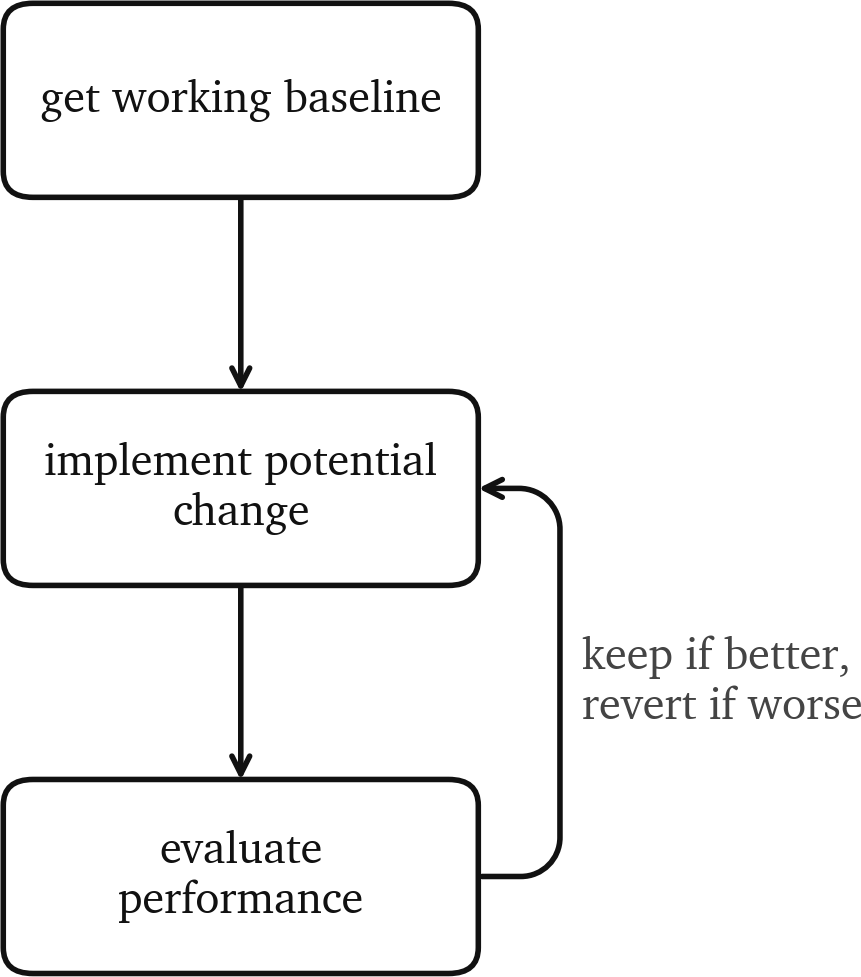
- Start with a working baseline.
- Make an expected improvement to the model, infrastructure, hyperparameters, data, etc.
- Evaluate it. If it is significantly better, keep it. Otherwise revert to the previous version.
- Repeat until satisfied.
Iterations are needed to get the model working well, but it’s difficult to tell when an improvement will actually be worth the effort before starting it. This extends to hyperparameter searches: pick different values of the hyperparameter for each test, run each test in parallel, pick the best one.
Every week there’s a new innovation published that claims to increase performance and it is very tempting to add a couple to your model, especially if you are on a budget and you aren’t hitting the numbers you want. However, neural networks can be a real pain to debug since many errors are inherently silent (opens in new tab), especially with training stability and data pipelining. The more code you add, the higher the risk of this, requiring even more time and code to fix.3As well, you can miss out on optimizations that have already been made for you. For instance, to add intra-document masking I had to switch from using PyTorch’s native FlashAttention to using FlexAttention which degraded performance. It wasn’t major at my scale but might have been if my budget was higher.
Be pragmatic: When deciding to add an improvement, the expected benefits of it must be greater than the effort and resources required (including debugging). Err on the side of not including something to keep the model leaner and easier to debug, and be stingy with what you do include. Determining the expected value comes from the literature (what others have said) and your own personal experience and intuition, which you will gain as you work on the project more and make more changes. But the cost of implementing it will depend on your project scale and how much human effort you have available. Each situation is different, and it’s not a guarantee you’ll get the same results as the literature.
For instance, I had wanted to add multi-GPU support in order to train faster. Since I wrote most of the infrastructure from scratch, adding this would require a full rewrite of my data pipeline, saving/loading bits, and training code. On top of that, multi-GPU nodes are less cost-efficient than using single-GPU.4The price of two hours on a machine with a single H100 on most cloud providers is less expensive than one hour on a machine with two H100s. Including other costs, it seems like if you have enough time and your model fits fine on one GPU, it isn’t worth it. While I really wanted to add it, it didn’t make sense for my purpose, so I didn’t.
On the other hand, take DeepSeek-V4, the incredibly efficient model released by DeepSeek in April 2026. Based on the whitepaper (opens in new tab) it seemed incredibly difficult to train due to the severe complexity. Most notably, the team had mixed the modern Muon optimizer, manifold-constrained hyperconnections, mixture-of-experts, a custom hybrid attention architecture, and 32+ trillion training tokens. They had to add lots of constraints, regularization, normalization, and other stability techniques just to get it to be stable. (Mentioning stability 24 times in their paper!)
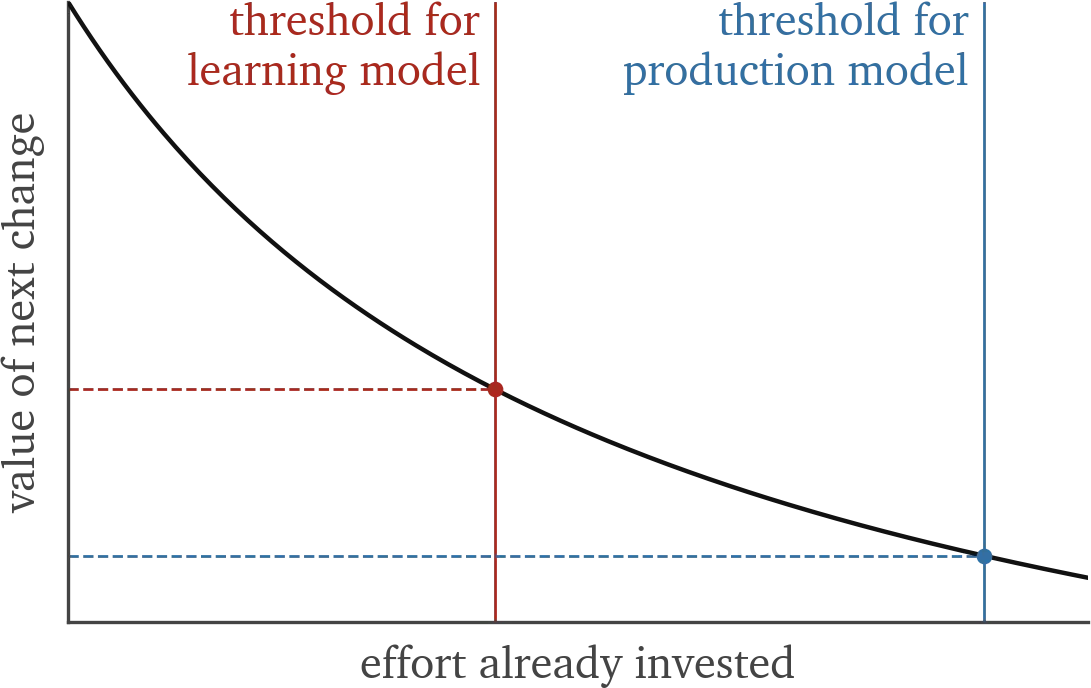
The shape of the diminishing returns curve is the same for everyone, but every team will have a different threshold of what’s worth it. For the DeepSeek team, it is valuable to put in that work to stay competitive by providing cheaper inference; for my project, anything beyond another rewrite would not see much benefit.
To show you the shape, here’s an estimate of the progress of my project. Four changes, which only changed ~13 lines of code, had the same impact as the rest of the changes, which involved heavy refactoring. (You may notice some changes were net-zero gain or even counter-productive - that was because I was not following this advice until after the fact!)
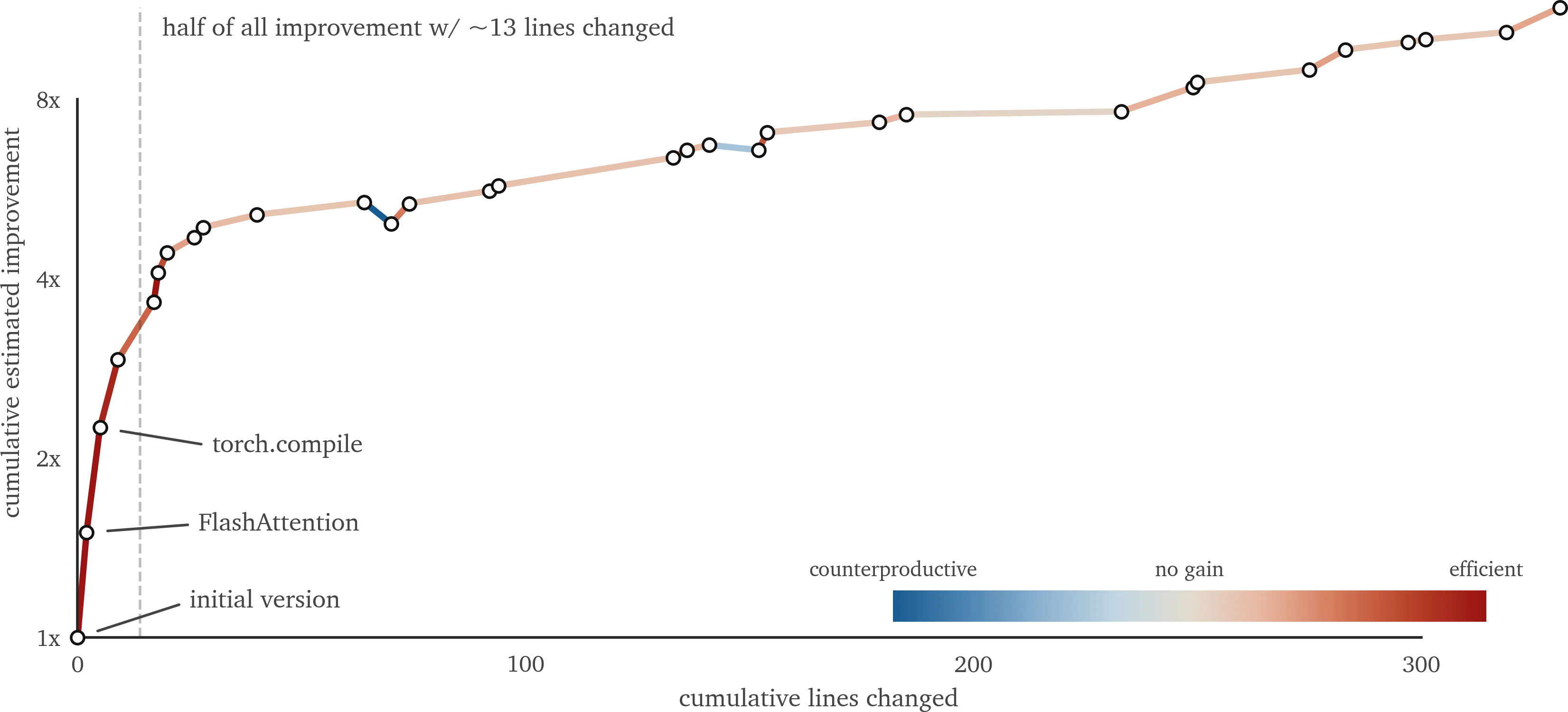
How to find the threshold
It is hard to determine when to stop the optimization process after you’ve added several working changes - given there’s so many levers to pull, how do you know you aren’t just shy of a really big improvement?
As you saw, there was a surprisingly small amount of major improvements, the rest were all incremental, each requiring an increasing amount of effort. The chart does not show changes I scrapped - which was a lot more than expected. Especially stuff outside the model code.
Example: I had scrapped over ten versions of a unified system to save and load models, vocabularies, experiments, and more. The reasoning I had was that by developing a perfect backwards-compatible multi-stage system, no information would be lost and each test would be more valuable. I spent maybe a month iterating over different versions, since I didn’t like any of them.
Of course that was a waste! I barely used any information besides what I learned from a test directly. My favorite version was the simplest one possible, that I made in fifteen minutes. I should have realized that this component of my system was not significant enough to put this much effort in.I think there is a benefit of being paranoid in ML, but maybe it’s best to only be paranoid with the ML and not the software engineering…
Prioritize data over literature and vibes
After you’ve added a change, you have to evaluate its performance to determine whether it actually is helpful.
I was hinting at this earlier, but this form of iterative testing is based on the ‘ablation test’: change one thing, measure it, then choose to keep or throw it out. Let’s break this down like that!
Only test one component at a time
An iteration loop can be useless if you test numerous improvements - how do you know what is actually causing benefits or performance loss? Testing an iteration with multiple changes provides a weak signal while testing an iteration with a single change is much stronger.
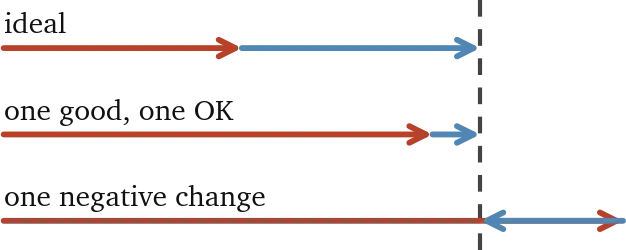 Three possibilities of the outcome of two changes in one test. The third can be eliminated by testing one change per test.
Three possibilities of the outcome of two changes in one test. The third can be eliminated by testing one change per test.
Imagine in one test for my project, I switched to a new fancy optimizer and added a new popular architecture change. Let’s say it shows great results. How would we know what actually contributed to that change? Maybe both were equally good, maybe one of those changes was incredibly good but the other was counteractive.
The benefit of grouping different tests into one loop is just to save test compute, assuming development time is the same. The cost is adding potentially bad changes and skipping potentially good changes.
The upshot is this: having fewer high-quality tests is better than more low-quality tests.
Evals
Isolating changes is easy in practice. The more difficult part is your measurements. Since each decision is made with respect to the evaluation, if you have poor tests or evaluation metrics, then the process breaks down.
Testing something like the speed of a new kernel or data pipeline is pretty easy since it’s evident right off the bat and has clear metrics (FLOP/s, tok/s, etc). But if it involves the architecture of the model, you have to train it and use a benchmark evaluation (eval) to see results, which are naturally proxies of what you actually want to measure.
By eval I don’t mean the final training loss or validation loss. While these are good metrics to determine good training, they aren’t particularly good at determining whether your model is doing what you want it to do. Essentially, it’s a held out dataset that you deem to be the best representation of what you want the final output to be, and you test against that.
There are lots of evaluation datasets available and what you pick should best reflect what you want, in both content and format.
In my project, I used three different benchmarks: one to test common sense reasoning (HellaSwag), one to test general knowledge (ARC-Easy), and a harder test of nuance in case the model finds the previous ones too easy (Winogrande). They are all multiple choice evaluation datasets that have been adapted to test next-token generative models by using a specific fill-in-the-blank esque format (cloze-form).
Every dataset pulls from a different source or has a different filtering procedure, and because of this datasets are naturally biased. Final performance, including evals, can be sensitive to this.6The one exception I make to being stingy about changes is with keeping datasets - adding small amounts of different (clean) datasets increases diversity, which is a bonus you can only see at the later stages of training. I noticed that increasing the proportion of one dataset (DCLM) would show improved performance in ARC-Easy. It seems like both are more biased towards STEM/academic knowledge content, and putting too much of it in the final training mix would make the model prefer academic terminology and rely on memorizing facts significantly more than what I wanted. I ended up including a non-negligible amount but favored more generalist datasets instead.
The bias problem can be fixed by using a suite of evals that fits what you want, and maybe make your own if you feel none are good enough. The next problem is each eval’s variance and whether it produces accurate relative results. Make sure you use a large sample size such that the variance is low enough to get good signal.
Another problem arises: if you train two variants you’re comparing, how do you know that the results are not based on other noise like the RNG seed, init, and data order? Would the results be significantly different if you used different random values?
As a model trains more, this noise decreases, and the eval can provide better signal. As mentioned earlier, you don’t have to fully train the model to get to a comparable state. I used 2.5B tokens for each ablation run (1/10th of full), which was on the shorter side, but was able to show signal for most tests. Even if you train longer than you think, expect the inevitable small amount of variance. If two tests perform around the same, the data can’t really help, and it’s better to pick the one you would prefer without the data / based on other evidence.
When evaluating what changes to keep, first follow your data. If you can’t get quality evals, then go to the literature for advice. If you get significantly different results than the literature, well it may be a bug, but if it isn’t, then you’ve found a unique result!
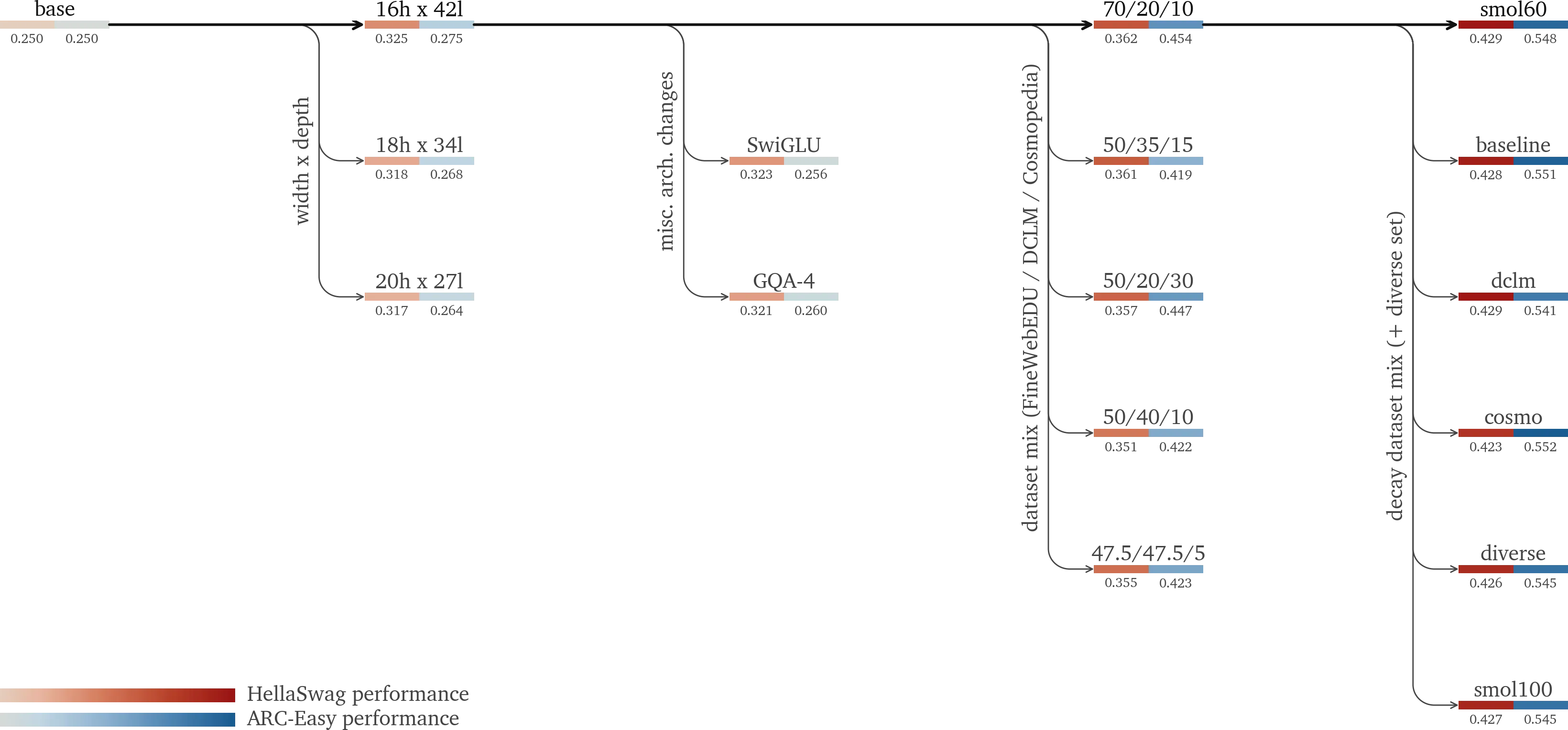
For instance, I was testing out different ratios of width vs depth for my model. I noticed most models similarly sized like mine picked a relatively balanced ratio. However, based on doing a sweep of different values (note I tweak each such that the total parameter count stays in the same ballpark), the best-performing one was the one that went all-in on depth (depth of 42 blocks!). Pretty cool I found it! Below is a DAG of some of the ablations I did and their respective performance on HellaSwag and ARC-Easy. Notice how tight the differences are!
Other tips (especially if you’re learning)
There’s a bunch of other things I learned from this project, but they mostly apply within the specific case of working on a project to learn or explore. I figure most people reading this wish to do these projects. I’ll put it in bullet points since this post is already getting too long…
As someone learning, your goal is to gain the intuition to make decisions easier and be able to debug faulty networks. Based on this,
Favor not writing the project from scratch. Trust me, I love starting projects from scratch, but the time taken on working and debugging infrastructure stuff took away from the juicy bits of learning. Using well-regarded public libraries that handle the brunt of it is a great way to avoid that! First decide what you actually want to learn or do, then build from scratch if genuinely necessary. You should write the model code yourself though, since that’s the best part! More specifically, avoid rewriting wandb, datasets, and tokenizers (unless you want to learn parallelized byte-pair encoding). I tried all three, and it provided very little learning besides the feeling of ownership.
In an extreme example, if you want to learn about training dynamics, you will waste a lot of time if you decide to rewrite Pytorch from scratch - even though learning how to write kernels and automatic differentiation engines is VERY useful, at some point you will spend much more time working on that part than the training dynamics part. Better to save it after you’ve nailed the training and want to maximize performance.
Start on a proper baseline before iterating away. Having a good baseline means you know what you start with works. That starts with the boring widely-used choices. For a transformer this is AdamW for optimization, dense attention akin to the decoder from the original paper + FlashAttention + RoPE, and the Fineweb-EDU dataset, and not much else.7For fun, I also trained the first version of this project on text from Freud and created this: What we cannot speak of, we inevitably dream. The mind protects itself by means of the dream phantasy. There were some others that were not very PG, maybe you can guess what they said… When something breaks, you’ll know that it is your changes and not the baseline. Once you have a good understanding of ‘normal’ then diverging is good.
Don’t scale until you have a working smaller version. This project was overscaled for my budget because I wanted to overscale it. I learned some things about scale, but it was not worth it since I wasn’t able to train my model as long as I wanted to (much more than the Chinchilla compute-optimal ~20 tok/param), and had to cut it due to my budget. Instead, working with smaller models and scaling those up within your means is a great way to conceptualize scaling laws. I’d only truly scale up if you see great promise in an already-existing project that you didn’t intend to scale initially, or you have the means to throw a bunch of money at a toy project just to learn some stuff. Eg. I started this project with a much easier to manage 27M parameter model then a 100M parameter model, both of which I could train on my laptop. It made transitioning to 500M parameters a lot easier by hardening many steps before I had to tackle much larger problems like working with GPU cloud providers.
Try lots of things! Larger projects like this are great but I would have much preferred a bunch of smaller projects. Each one will build up your intuition more and since the cost is much lower, you can throw a lot more at experimenting!
Don’t be afraid to make mistakes. Especially when you’re doing a lot of ablation tests, you can make a lot of mistakes, or feel like many of them didn’t lead to anything since they weren’t good. Those are all great learning experiences! Eg. because of a botched group of tests with batch sizes, I can tell someone in detail about the relation between batch size and learning rate. It wouldn’t have solidified properly if I didn’t see it in action and just read it from a book.
Conclusion
If there’s a TL;DR of this post it’s to stay principled. Every decision you make should be deliberate and backed by proper data and literature. It’s easy to skimp on this when trying to just get it to work or you don’t like how well the model is performing but I hope I’ve convinced you otherwise.
The model I worked on (and yes I know, I barely talked about it) is only pretrained. The steps that make it useful, namely supervised fine-tuning and reinforcement learning, are a large part of it, but I omitted it since my goal was to learn about pretraining. I’d like to cover them (with a more technical writeup of the project) in a later post if time permits.
Thanks for reading! If any of the implementation details interest you, the full code is here (opens in new tab).
Resources
Here’s a list of resources I found helpful when I was working on this project, and focuses more on the technical aspects of doing a project like this.
- Obviously, this project was based on the original “Attention is All You Need (opens in new tab)” paper by Vaswani et al.
- Welch Labs “How DeepSeek Rewrote the Transformer (opens in new tab)” does a great job explaining the transformer architecture and DeepSeek’s variant, MLA, visually.
- Andrej Karpathy’s video “Let’s build GPT: from scratch, in code, spelled out. (opens in new tab) was the inspiration of the first version of my model.
- Karpathy also has a great resource, “A Recipe for Training Neural Networks (opens in new tab)”, that is like this post but has a lot more technical guidance.
- A detailed guide on how to train a transformer model akin to frontier laboratories can be found from the HuggingFace team’s “Smol Training Playbook (opens in new tab)” and derivative work ‘frontier model training methodologies (opens in new tab)” by Alex Wa, both of which I relied on when scaling up this project.